LayoutTransformer - Layout Generation with Self-attention
ICCV 2021
1University of Maryland, College Park
2Amazon AWS
Abstract
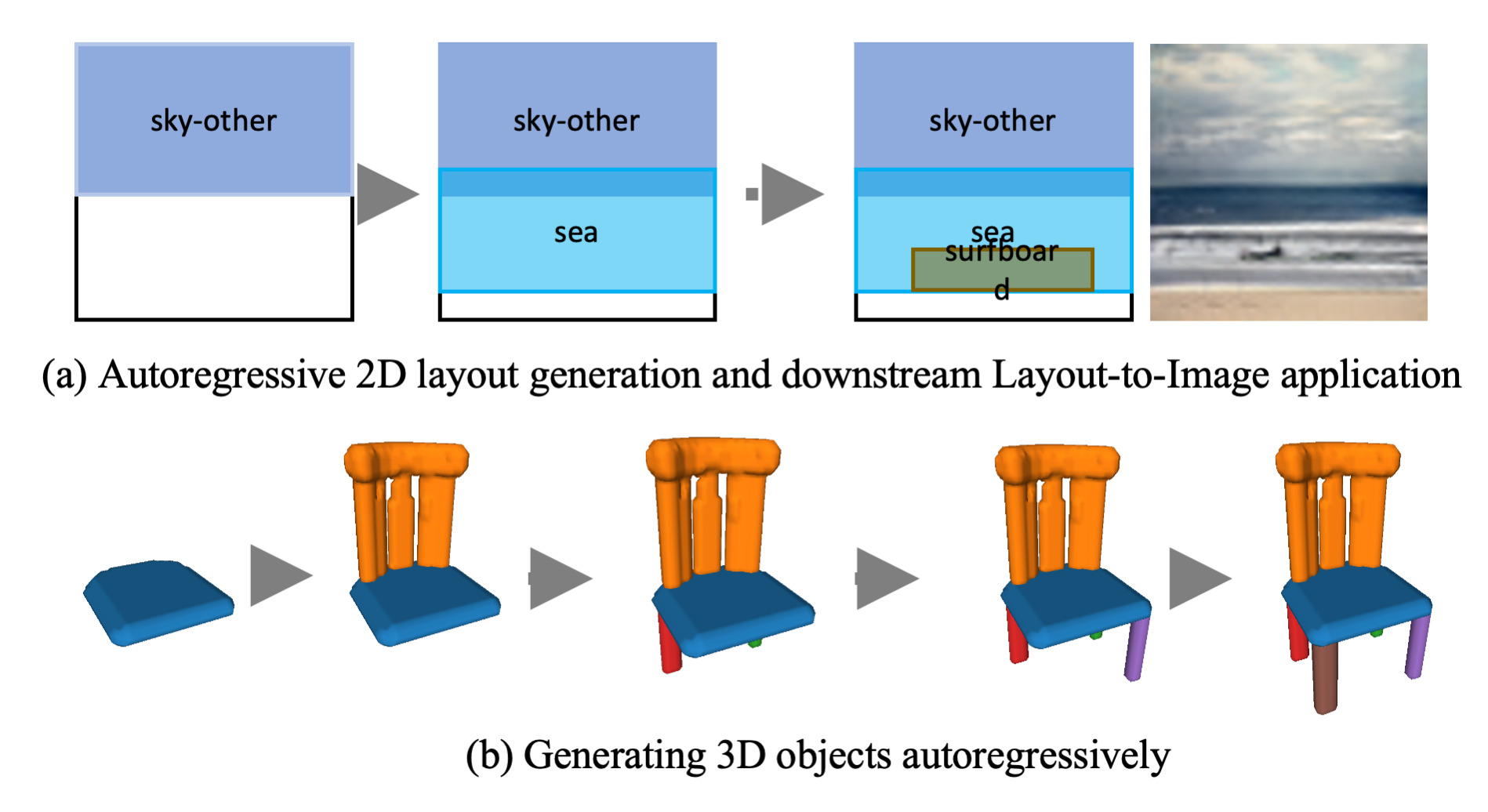
We address the problem of scene layout generation for diverse domains such as images, mobile applications, documents, and 3D objects.
Most complex scenes, natural or human-designed, can be expressed as a meaningful arrangement of simpler compositional graphical primitives.
Generating a new layout or extending an existing layout requires understanding the relationships between these primitives.
To do this, we propose LayoutTransformer, a novel framework that leverages self-attention to learn contextual relationships between layout elements and generate novel layouts in a given domain.
Our framework allows us to generate a new layout either from an empty set or from an initial seed set of primitives, and can easily scale to support an arbitrary of primitives per layout.
Furthermore, our analyses show that the model is able to automatically capture the semantic properties of the primitives.
We propose simple improvements in both representation of layout primitives, as well as training methods to demonstrate competitive performance in very diverse data domains such as object bounding boxes in natural images(COCO bounding box), documents (PubLayNet), mobile applications (RICO dataset) as well as 3D shapes (Part-Net).
Cite
@inproceedings{gupta2020layout,
title={LayoutTransformer: Layout Generation and Completion with Self-attention},
author={Gupta, Kamal and Achille, Alessandro and Lazarow, Justin and Davis, Larry and Mahadevan, Vijay and Shrivastava, Abhinav},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year={2021}
}
Last updated on July 25, 2021